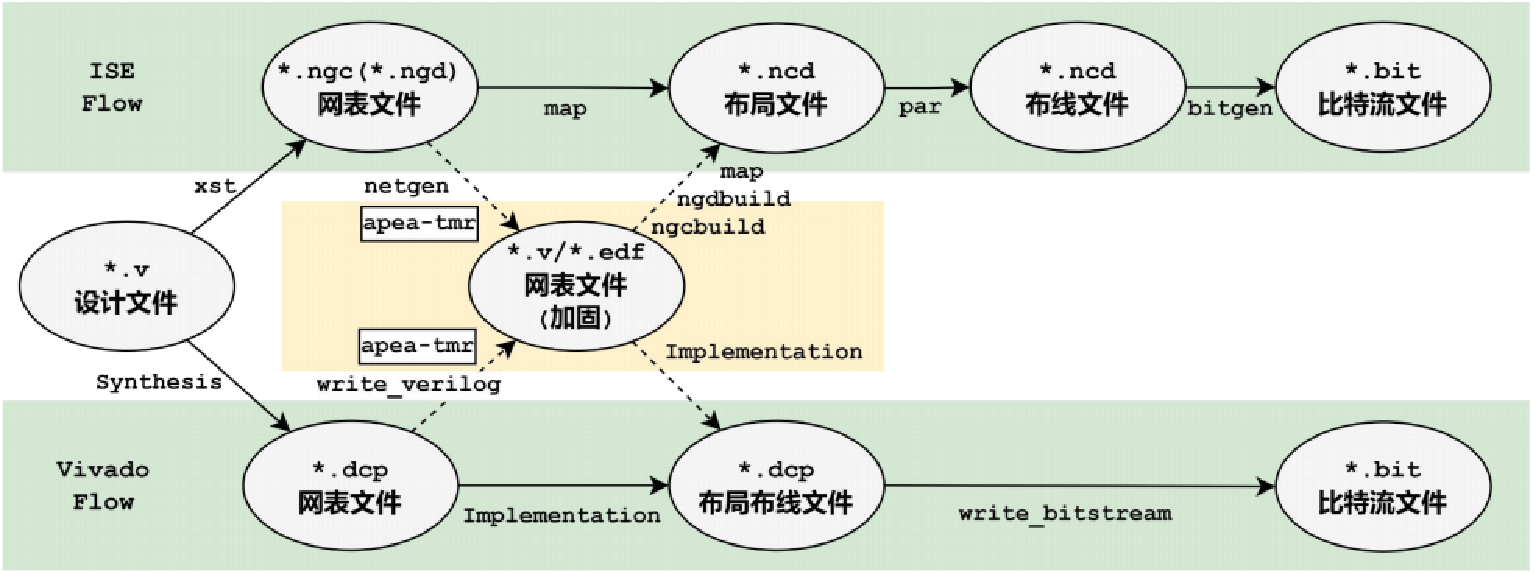
复杂大容量FPGA 正向工具链 Dimension是深维科技开发的一款面向高端大容量FPGA正向设计的全流程工具链;现阶段具备的功能包括:功能完备的语法分析器,支持Verilog-2001和VHDL-93;优秀的逻辑综合优化引擎,支持1000K+规模的设计;支持XC5VLX110T、XC7K325T等器件;优化设计的布局布线基础架构和算法,大幅提升运行速度;无缝兼容ISE设计流程;基于云服务的多功能IDE。 低费效比FPGA TMR加固工具 TMR工具原生支持深维科技自主研发的复杂大容量FPGA正向设计工具,同时还兼容市面常用的EDA工具 ,如ISE和Vivado;能够在不改变开发流程的前提下,对用户设计进行方便快捷的三模加固。当前功能:支持LTMR、DTMR、GTMR等既定策略;支持使用规则文件对设计进行高度自定义的加固;多种智能加固策略;兼容ISE、Vivado设计流程;支持导出形式化验证脚本 ,可借助Formality进行加固前后的等价性验证;基于云服务的多功能 IDE。 下一代图片处理 SaaS API方案 2021.2月,赛灵思举办了一场主题为:大显身手之助攻图片转码加速的直播活动。深维科技CEO樊平受邀参加此次活动,并围绕图片应用发展趋势、动图需求与解决方案、静态图片需求与解决方案、深维在图片加速产品里的关键技术等几方面为大家带来精彩内容。 图片处理的挑战与解决方案 播放视频 图片内容广泛应用于互联网应用,高品质图片服务能够显著提升用户体验,用户活跃度,成单率等。随着图片分辨率快速提升和广泛应用,海量图片的处理面临巨大的挑战。深维科技CEO樊平携手浪潮元脑公开课,与您一同探讨如何一站式解决图片处理所面临的各类挑战。 近期动态 深维科技出席2024 CCF中国软件大会 FPGA可靠性设计自动化技术成果亮相展会 2024年中国工业计算机大会,深维科技如约而至 喜报!深维科技-北京大学合作团队在FPGA’24布线加速竞赛中夺得佳绩! 我司与北大EDA研究院签订战略合作协议 深维科技受邀参加CCF DAC 2023,助力FPGA共性技术发展 热烈祝贺深维科技首席科学家罗国杰博士当选CCF容错计算专委新一届常务委员 关于深维科技 使命 公司积极响应国家“自主可控”和解决“卡脖子”问题的号召和要求,凭借着在FPGA行业近20年的技术积累和优势资源,致力成为国内领先的复杂大容量FPGA国产EDA平台和安全可靠性解决方案供应商,为装备的自主可控、芯片层级安全可靠性等提供技术支撑和产品服务。 聚焦 公司关注客户痛点和致力核心技术攻关,围绕解决复杂大容量FPGA的开发设计环境、芯片性能提升和可靠性及安全保证等问题,为空天、航天、航空、核工业、船舶、电力、汽车和通信等行业,提供复杂大容量FPGA的国产正向设计EDA、可靠性加固、代码漏洞与缺陷检测、IP及相关硬件、设计与验证、设计环境建设与优化等工具平台和技术服务。 合作 随着集成电路产业的发展,设计规模越来越大,制造工艺越来越复杂,未来EDA生态将面临更多的机遇和挑战。在技术“卡脖子”的背景下,国产替代迫在眉睫,并随着芯片设计公司数量及规模的快速增长和需求拉动下,其行业前景可期和可观。展望未来,为助力FPGA共性技术的突破和创新,助力EDA生态系统的建设和发展,助力集成电路产业的繁荣和强盛,我们愿与行业伙伴们携起手来,共享资源、技术和知识,共同推动技术创新和应用推广,共谋发展,共建生态,共担国产化发展重任! 合作伙伴














")

